NUMAって、そもそもナニ?
はじめに
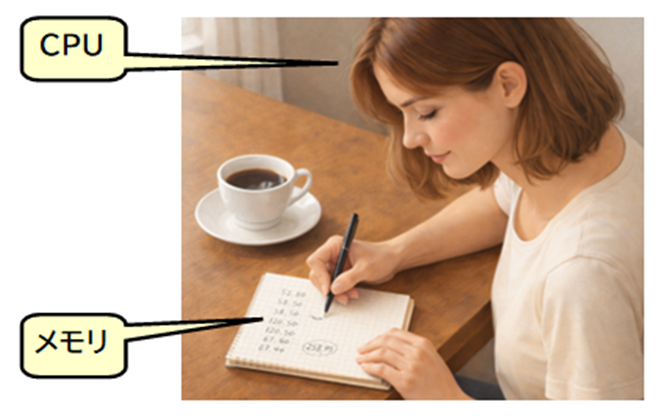
コンピュータの中には、大きく分けて 「CPU(処理装置)」 と 「メモリ(記憶装置)」 があります。
CPUは「計算する人」、メモリは「作業台の上に広げたメモ帳」だとイメージしてください。
この構成では、CPUはメモリのどこにでも 同じ速さ でアクセスできます。シンプルで分かりやすいですね。これを専門用語で UMA(Uniform Memory Access=均一メモリアクセス) と呼びます。「どこも均一だよ」という意味です。
CPUが2個以上になると何が起きる?
最近のサーバーや高性能なPCでは、CPUが 2個、4個、それ以上 搭載されていることがあります。
「じゃあメモリも全部まとめて、みんなで仲良く使えばいいじゃん!」…と思いますよね。ところが、これが 意外とむずかしい のです。
問題:メモリを全員で共有すると「渋滞」が起きる
CPUが増えれば増えるほど、メモリへのアクセスが集中します。まるで、一本道の橋に車が殺到するような状態です。
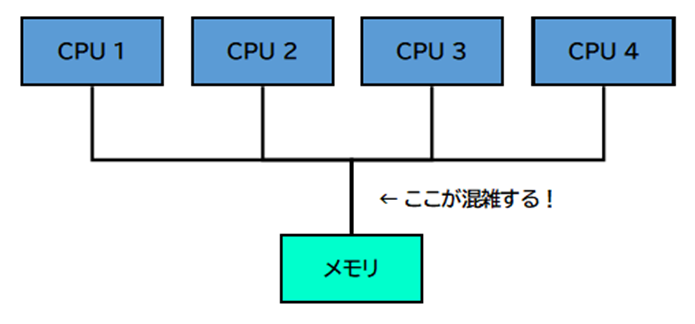
CPUを増やしても、メモリへの「道」がボトルネックになって、期待通りに速くならない…というジレンマが生まれます。
そこで登場!NUMA(ヌーマ)
NUMA とは Non-Uniform Memory Access、日本語にすると 「不均一メモリアクセス」 の略です。
「不均一」というのがポイント。「わざとえこひいきする仕組み」と言い換えてもいいかもしれません。
NUMAの発想:「近くにメモリを置こう」
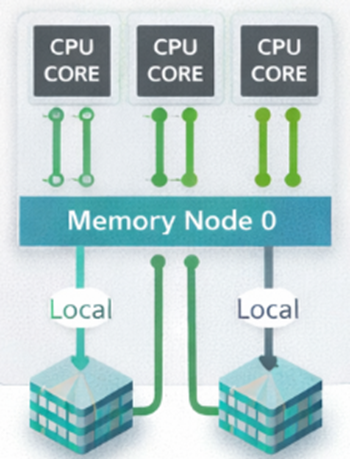
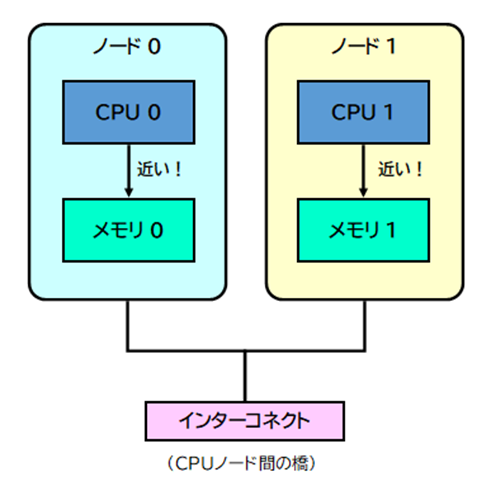
NUMAでは、それぞれのCPUに 「自分専用の近いメモリ」 を割り当てます。
このCPU+メモリのひとかたまりを 「NUMAノード」 と呼びます。
近いと遠い、これがNUMAの核心
NUMAでは、メモリへのアクセス速度が 「どこのメモリか」によって変わります。
| アクセス先 | 距離 | 速度 |
| 自分のノードのメモリ | 近い | 速い |
| 別のノードのメモリ | 遠い | 遅い |
具体的にどのくらい違う?
別ノードのメモリへのアクセスは、ローカルと比べて 1.5〜3倍程度遅くなる こともあります。
これを 「NUMAの距離(NUMA Distance)」 と呼び、数値で管理されています。

自分自身は「10」、隣のノードは「21」、遠いノードは「31」といった具合です。
なぜNUMAで性能が上がるの?
「均一じゃない方が不便じゃないの?」と思うかもしれません。
でも、こう考えてみてください。
大きなオフィスで、書類を取りに行くとき…
- 自分のデスクの引き出し(近いメモリ) → すぐ取れる
- 別のフロアの倉庫(遠いメモリ) → 時間がかかる
NUMAは「なるべく自分の引き出しを使う設計」にすることで、渋滞を避けつつ高速化を実現しているのです。

OSやアプリはNUMAをどう扱っている?
NUMAは「ハードウェアの仕組み」ですが、OS(オペレーティングシステム) がうまく活用してくれています。
- LinuxはNUMAを認識し、プロセスをなるべく ローカルメモリで動かす よう制御します
- numactl というコマンドで、「このプログラムはノード0で動かして!」と指定することもできます
- データベース(PostgreSQL、MySQLなど)や仮想化基盤(VMwareなど)も、NUMA対応の最適化を行っています
まとめ:NUMAを一言で言うと
「複数のCPUそれぞれに専用メモリを持たせて、近くのメモリは速く・遠くのメモリは少し遅く扱う設計のこと」
| 用語 | 意味 |
| NUMA | Non-Uniform Memory Access(不均一メモリアクセス) |
| UMA | Uniform Memory Access(均一メモリアクセス)← NUMAの対義語 |
| NUMAノード | CPU+メモリのひとかたまりの単位 |
| ローカルアクセス | 自分のノードのメモリへのアクセス(速い) |
| リモートアクセス | 別ノードのメモリへのアクセス(遅い) |
| NUMA Distance | ノード間のアクセス遅延を示す指標 |
最後に
NUMAは最初は「なんだか複雑そう…」と感じるかもしれませんが、本質はシンプルです。
「自分の近くにあるものを使う方が速い」
これは、コンピュータの世界でも、私たちの日常でも、同じ原理なのです。サーバーの性能チューニングや、クラウド基盤の話を聞くときに「あ、NUMAの話だな」とピンとくれば、この読み物の目標は達成です!

