パラレルファイルシステムって、そもそもナニ?
はじめに
パソコンで文書を保存するとき、私たちは何も考えずに「Ctrl+S」を押します。でも、その裏側では「データをどこに、どうやって書き込むか」という複雑な処理が行われています。普段使いのパソコンでは、それで十分です。でも・・・
「1秒間に1テラバイトのデータを読み書きしたい」
「1000台のコンピュータが同時に同じデータにアクセスしたい」
となったら、どうすればいいでしょう?
これが、パラレルファイルシステム(Parallel File System) が解決しようとしている問題です。
ファイルシステムとは?
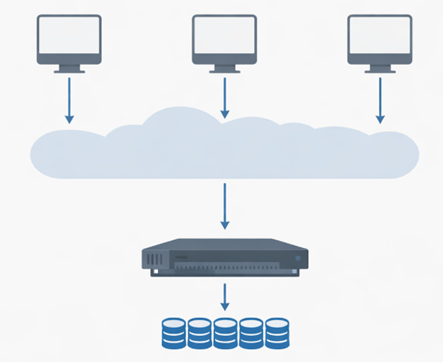
身近な例:ハードディスク1台の世界
皆さんのパソコンには、たいていWindowsなら NTFS、Macなら APFS というファイルシステムが使われています。これらは「1台のディスクに、1台のコンピュータがアクセスする」ことを前提に作られています。イメージとしては、こんな感じです。

1本道なので、速さには限界があります。道路が1車線しかなければ、どんなに急いでも渋滞します。それと同じです。
「ネットワーク越しに使えるファイルシステム」もある
会社や学校では、NAS(ネットワーク接続ストレージ)や、NFS・SMB といったネットワークファイルシステムを使うことがあります。これは「離れた場所にあるディスクを、まるで自分のPCのディスクのように使う」技術です。でも、これも基本的には1台のサーバーがボトルネック(詰まりどころ)になります。アクセスが集中すると、やはり遅くなってしまいます。
そこで登場!パラレルファイルシステム
「パラレル(Parallel)=並列」がポイント
パラレルファイルシステムは、ひとことで言うと——
「複数のサーバー・複数のディスクに、複数のコンピュータが同時並行でアクセスできるファイルシステム」
です。先ほどの道路の例えで言うなら、1車線の道路を何十車線もの高速道路に変えるようなイメージです。

データを複数のストレージに分散して置くことで、たくさんのコンピュータが同時に、しかも高速にデータを読み書きできるようになります。
どんな場所で使われているの?
パラレルファイルシステムは、主にスーパーコンピュータや大規模な科学計算の現場で活躍しています。
| 場所 | 何をしているのか |
| 気象予報機関 | 天気予報のシミュレーション計算 |
| ゲノム研究所 | 遺伝子データの大量解析 |
| 宇宙研究機関 | 宇宙物理シミュレーション |
| AI研究所 | 深層学習モデルの大規模訓練 |
| 自動車メーカー | 衝突シミュレーション計算 |
たとえば、気象予報のシミュレーションでは、気温・気圧・湿度などを地球全体のマス目に分割して、何千台ものCPUが一斉に計算します。そのとき、各CPUが「自分の担当エリアのデータ」を素早く読み書きする必要があります。こういう場面でパラレルファイルシステムが欠かせないのです。
代表的なパラレルファイルシステム
Lustre(ラスター)
Lustreは、世界で最も広く使われているパラレルファイルシステムのひとつです。オープンソースで開発されており、多くのスーパーコンピュータに採用されています。
日本での身近な例:
- 理化学研究所の「富岳(ふがく)」などのスーパーコンピュータ
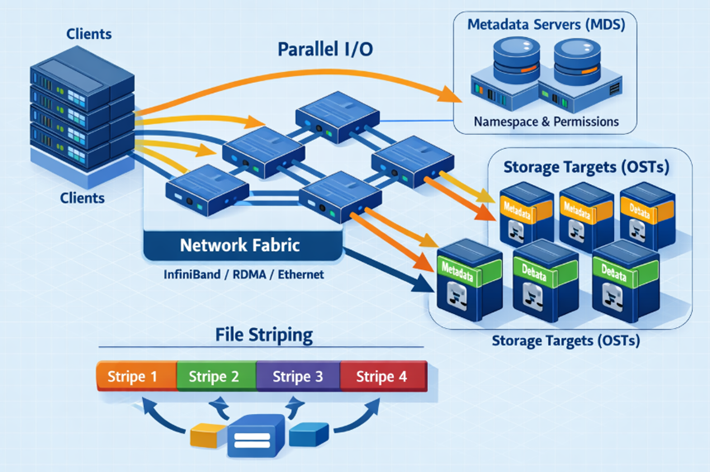
Lustreの仕組みをざっくり理解する
Lustreは役割を分担する構造になっています。
| MDS(メタデータサーバー) | OSS/OSSs(オブジェクトストレージサーバー) |
| ・ファイルの名前、場所、属性を管理 ・図書館の「目録カード」に相当 | ・実際のデータを分散して保管 ・図書館の「本棚(本)」に相当 |
たとえば100GBのファイルを読むとき——
- まず MDS に「このファイルはどこにある?」と聞く
- MDS が「OSSの①③⑤⑦番に分散してあるよ」と教えてくれる
- クライアント(利用者のPC)が OSSたちに直接、同時並行でアクセス
- 複数のディスクから一斉にデータが流れ込んでくる → 超高速!
GPFS / IBM Spectrum Scale(ジーピーエフエス)
GPFS(General Parallel File System)は、IBMが開発した商用のパラレルファイルシステムです。現在は IBM Spectrum Scale という名前でも知られています。
特徴:
- 高い信頼性と安定性(金融機関や大企業でも採用)
- 容量の自動管理(ティアリング:よく使うデータは高速ストレージ、古いデータは低速ストレージに自動移動)
- クラウド環境との連携にも強い
Lustreとの違いは?
| 比較項目 | Lustre | GPFS/Spectrum Scale |
| 種別 | オープンソース(無償) | 商用(有償) |
| 強み | 超高速・超大規模 | 信頼性・管理機能 |
| 主な用途 | スパコン・HPC | 企業・研究機関 |
| サポート | コミュニティ中心 | IBMによる商用サポート |
その他のパラレルファイルシステム
世の中にはこの2つ以外にも、様々な選択肢があります。
| 名前 | 開発元・特徴 |
| BeeGFS | 比較的導入しやすいオープンソース系。中規模HPCに人気 |
| PVFS / OrangeFS | 研究・教育目的でよく使われる老舗OSS |
| WekaFS | クラウドネイティブ対応のモダンな高速ファイルシステム |
| DAOS | Intelが開発。不揮発性メモリ(NVM)を活用した次世代型 |
「どうやって速くなるのか」をもっと詳しく
パラレルファイルシステムが速い理由は、大きく3つの仕組みがあります。
- ストライピング(データの分割・分散)
大きなファイルを「ストライプ」と呼ばれる小さな塊に切り分けて、複数のディスクに分散して置きます。
読み出すときは3台のディスクから同時に読めるので、理論上は3倍の速さになります。ディスクの台数を増やせば増やすほど、速度も上がっていきます。 - メタデータとデータの分離
「ファイルの名前・サイズ・更新日時」などのメタデータと、実際のデータ本体を、別々のサーバーで管理します。これにより、「ファイルを開く・一覧を見る」という軽い操作と、「データを大量に読み書きする」という重い操作が、互いに邪魔し合わなくなります。 - クライアントの直接アクセス
重要なポイントは、「データを読み書きするとき、クライアント(利用者のPC)がストレージサーバーに直接アクセスする」ことです。NASのような構成では、すべての通信が1台のサーバーを経由するため、そこがボトルネックになります。パラレルファイルシステムでは、コーディネートするサーバー(MDSなど)はあるものの、実際のデータのやり取りはクライアントとストレージが直接行います。
実際の性能は?
ちょっと数字で感じてみましょう。
| システム | 読み書き速度の目安 |
| 一般的なSSD(SATA) | 〜 500 MB/s |
| 高性能SSD(NVMe) | 〜 3,500 MB/s |
| 小規模Lustreクラスタ | 数十 GB/s |
| 大規模スパコン向けLustre | 数百〜数千 GB/s |
世界最高峰のスーパーコンピュータのストレージシステムでは、1秒間に数テラバイトもの読み書きを実現しているものもあります。映画のブルーレイディスク(約50GB)に換算すると、1秒間に数十枚分のデータが流れていることになります。
課題と注意点
もちろん、パラレルファイルシステムには難しい側面もあります。
- 構築・運用が複雑
サーバー、ネットワーク、ストレージを組み合わせるため、専門知識が必要です。「とりあえず使い始める」という訳にはいきません。 - 小さいファイルが苦手
「1バイトのファイルを100万個」のような、小さいファイルが大量にある場合は、パラレルファイルシステムの得意とするところではありません。メタデータへのアクセスが集中してしまいます。 - コストが高い
高速ネットワーク(InfiniBandなど)や大量のサーバーが必要なため、導入・維持コストは安くありません。 - 障害対応が難しい
構成要素が多いため、どこかが壊れたときの影響範囲の特定や復旧が複雑になることがあります。
最近のトレンド:クラウドとの融合
最近では、クラウドコンピューティングの普及とともに、パラレルファイルシステムも進化しています。
- クラウド上でLustreを使う(Amazon FSx for Lustre など)
- オンプレミス(自社設備)とクラウドのハイブリッド構成
- AIワークロード向けに特化した高速ストレージ(機械学習の学習データを高速配信するなど)
また、NVMe over Fabrics(NVMe-oF) のような技術により、ネットワーク越しでもNVMeの速さを活かせる仕組みも広がっています。「ストレージ=遅い」という常識が、どんどん塗り替えられています。
合わせて読みたい
まとめ
最後に、今回学んだことを整理しましょう。
| ポイント | 内容 |
| パラレルファイルシステムとは? | 複数のストレージに複数のPCが同時並行でアクセスできるファイルシステム |
| なぜ速いのか? | データをストライピング(分散)し、並列に読み書きするから |
| 代表的なもの | Lustre(OSS)、GPFS/Spectrum Scale(IBM商用)など |
| どこで使われる? | スパコン、AI研究、気象計算、ゲノム解析など大規模計算の現場 |
| 弱点は? | 構築・運用の複雑さ、小ファイルの苦手さ、高コスト |
おわりに
「ファイルシステム」と聞くと地味に聞こえるかもしれませんが、スーパーコンピュータや最新のAI研究を支える縁の下の力持ちがパラレルファイルシステムです。
ChatGPTのような大規模な言語モデルを訓練するとき、天気予報の計算をするとき、創薬のシミュレーションをするとき——その裏側では、何百台ものストレージが一斉にデータを読み書きしています。
データがますます巨大化するこれからの時代、パラレルファイルシステムの重要性はさらに高まっていくことでしょう。