NVLink/NVSwithって、そもそもナニ?

はじめに
最近、ChatGPTや画像生成AIのニュースを見ていると、やたらと「GPU」という言葉が出てきますよね。GPUとは、もともとゲームの映像処理のために生まれた半導体チップですが、いまやAIの計算をこなす頭脳として大活躍しています。ところが、AIモデルがどんどん巨大化するにつれて、1枚のGPUでは処理しきれないという問題が起きてきました。
たとえば、ChatGPTのようなAIを動かすには、数百億〜数千億個のパラメータ(重みとも呼ばれる数値)をメモリに載せて計算する必要があります。1枚のGPUのメモリ容量は、たとえ最高級品でも80〜192GB程度。これでは全然足りません。そこで発想されたのが、「複数のGPUをつなげて、1つの大きなGPUとして使ってしまおう」 というアイデアです。
この「GPUとGPUをつなぐ技術」こそが、今回のテーマ NVLink です。
PCIe (PCI Express)との比較
GPUはふつう、マザーボード上の PCIe(ピーシーアイ・エクスプレス) というスロットに挿して使います。PCIeはCPUとGPUをつなぐ「道路」のようなものです。
でも、この道路には限界があります。
| PCIe 5.0 (x16) | NVLink 4.0 | |
| 帯域幅(双方向) | 約128GB/s | 約900GB/s |
| 主な用途 | CPU ⇔ GPU | GPU ⇔ GPU |
帯域幅とは「1秒間にどれだけのデータを運べるか」という道路の広さのことです。NVLinkはPCIeの 7倍以上 の広さを持っています。
PCIeで複数のGPUをつないでも、データのやり取りが遅すぎて、GPUたちがお互いに「待ち」の状態になってしまうのです。渋滞した1車線の道路で大型トラックを走らせようとするようなイメージです。
合わせて読みたい
NVLinkとは?
NVLink(エヌブイリンク)は、NVIDIA社が開発した GPU同士を高速につなぐための専用インターフェース(接続規格)で、ざっくり言うとこういうものです:
GPU と GPU を、超高速の専用ケーブル(または直結)でつなぐ技術
NVLinkでつながったGPUは、お互いのメモリを まるで1つの大きなメモリのように使うことができます。
たとえば、80GBのメモリを持つGPUを8枚NVLinkでつなぐと、合計 640GBのメモリ空間 として扱えます。これで、巨大なAIモデルもどんと来い!というわけです。
NVLinkのバージョン歴史
| バージョン | 登場年 | 代表的なGPU |
| NVLink 1.0 | 2016年 | Tesla P100 |
| NVLink 2.0 | 2018年 | Tesla V100 |
| NVLink 3.0 | 2020年 | A100 |
| NVLink 4.0 | 2022年 | H100 |
| NVLink 5.0 | 2024年 | B100/B200 (Blackwell) |
世代を重ねるごとに、どんどん速くなっています。
NVSwitchとは?
さて、ここで新たな問題が生まれます。NVLinkで2枚のGPUをつなぐのは簡単です。でも、8枚・16枚・何十枚ものGPUを全部つなぎたいとしたら?
GPU1番とGPU2番、GPU1番とGPU3番、GPU2番とGPU3番……と全部の組み合わせで直接つなごうとすると、接続の数が爆発的に増えてしまいます。8枚なら28本、16枚なら120本!配線が大変なうえ、GPUのポートも足りません。
そこで登場するのが NVSwitch(エヌブイスイッチ)です。NVSwitchは、複数のGPUをまとめてつなぐための「ハブ(交換機)」 です。ネットワークのスイッチングハブと同じ役割、と思えばわかりやすいでしょう。
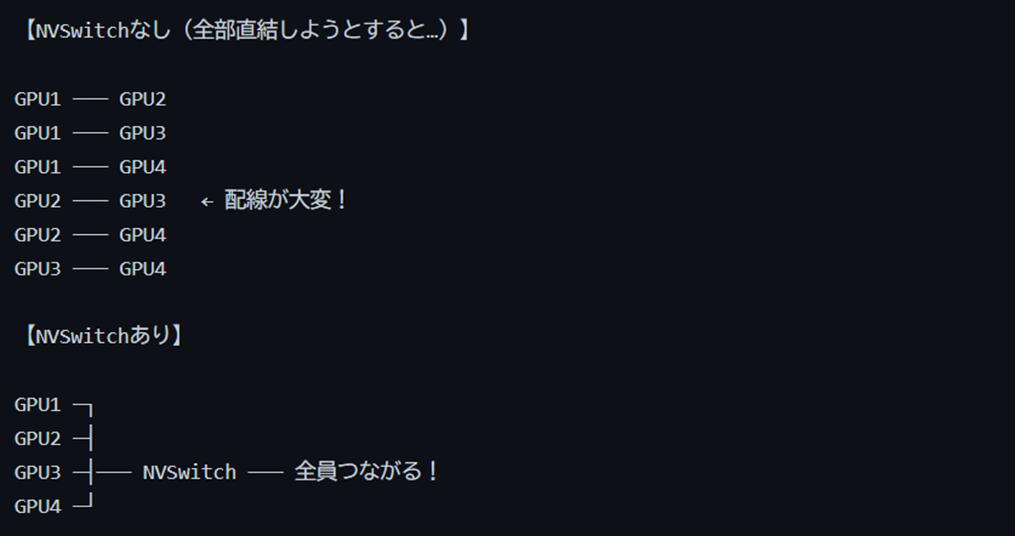
NVSwitchを使うと、どのGPUからどのGPUへも、NVSwitchを通じて高速にデータを送り届けられます。まるで空港のハブのようなイメージです。
| 技術 | 役割 | たとえるなら |
| NVLink | GPU同士をつなぐ「高速道路の規格」 | 道路そのもの |
| NVSwitch | 多数のGPUをまとめる「交差点・ハブ」 | インターチェンジ |
この2つはセットで使われることが多く、一緒になってはじめて「たくさんのGPUが1つの巨大GPUのように動く」世界が実現します。
実際にどこで使われているの?
NVLinkとNVSwitchは、主に データセンターや研究機関向けの製品 に搭載されています。
DGXシステム(NVIDIAの超高性能AIサーバー)
NVIDIAが販売する DGX H100 というサーバーは、H100 GPUを8枚搭載し、それらがNVLinkとNVSwitchでガッチリ接続されています。このサーバー1台で、まるで GPUが1枚の超巨大チップ のように協調して動きます。
NVIDIAのスパコン「DGX SuperPOD」
さらに大きなシステムでは、DGXサーバーを何十台・何百台と並べ、NVLink Switch System(旧称:NVLink Network) という仕組みでラック間もつないでしまいます。もはやデータセンター全体が1つのGPUのような存在になるわけです。
一般ユーザには関係無い?
「そんな話、自分には縁がないな」と思った方、実はじわじわと身近になってきています。
- クラウドサービス(AWS、Google Cloud、Azure など)でNVLink世代のGPUを使ったAIサービスが急増中
- あなたが使っているAIツールの「裏側」では、NVLinkでつながったGPU群が今日も動いている
まとめ
| キーワード | ひとことで言うと |
| NVLink | GPU同士を超高速でつなぐ専用の道路 |
| NVSwitch | 多数のGPUをつなぐ高速なハブ |
| なぜ必要か | PCIeでは遅すぎて、巨大AIの計算に追いつけないから |
| 何が嬉しいか | 複数GPUのメモリを1つにまとめ、超大規模なAI計算が可能になる |
NVLinkとNVSwitchは、「AIがすごい」と言われるこの時代を支える縁の下の力持ちです。ChatGPTに何か話しかけるたびに、どこかのデータセンターでこの技術が黙々と働いていると思うと、ちょっと感慨深くありませんか?

